Two gives.
One ask.
A longevity stack.
Six compounds I actually run.
Not medical advice. Talk to your doctor before any of this — especially the last two.
Six levers on one machine:
cellular repair.
A moved biomarker is not
a longer life.
NMN — refill the cell's
energy currency.
The mechanism
NAD+ powers energy metabolism and cell repair, and declines ~40–50% by age 50. NMN reliably raises it; small RCTs show modest gains in gait, muscle function, and insulin sensitivity.
The double edge
NAD-supported DNA repair may help prevent cancer starting — nicotinamide cut new skin cancers 23% in the ONTRAC RCT. But NAD+ can also feed an existing tumor. Direction depends on what's already there.
Bottom lineReliable on the biomarker, modest on function, genuinely two-sided on cancer.
GlyNAC — rebuild the master
antioxidant.
The mechanism
Restores age-depleted glutathione — the body's main intracellular antioxidant — by supplying its two rate-limiting precursors, glycine and N-acetylcysteine. Improves strength, gait, and oxidative-stress markers.
The evidence & dose
Small RCT (n=24): gait speed +19%. Mouse lifespan +24%. Trials use ~7g glycine + 7g NAC/day — far above most off-the-shelf products. Well tolerated.
Bottom lineCoherent mechanism, encouraging small human data — but the dose that worked is much higher than most labels.
Creatine — the best-evidenced
compound on this list.
The mechanism
Phosphocreatine buffers ATP. The longevity angle isn't the gym — it's countering sarcopenia, the age-related muscle loss that drives frailty. Some cognitive benefit under stress or sleep deprivation.
The evidence & watch
Meta-analysis (22 RCTs): +1.37 kg lean mass with resistance training; cognition mixed. 3–5g/day monohydrate, strong safety record. Watch: a benign creatinine rise can be misread as a kidney issue — flag it to your doctor. Benefit needs the training.
Bottom lineProven, cheap, safe. If you take one thing off this list, it's this.
Urolithin A — clear out the
broken mitochondria.
The mechanism
A gut metabolite of pomegranate and walnut that triggers mitophagy — the recycling of damaged mitochondria. Only ~40% of people make it on their own, which is why you supplement the finished molecule.
The evidence & dose
RCTs: ~12% strength gain, lower CRP, better muscle endurance in older adults. One of the better-evidenced newer compounds. 500–1000mg/day standardized (Mitopure); FDA GRAS, well tolerated.
Bottom lineNewer, but the human data is real and the safety profile is clean.
Lithium — a trace dose,
35–45× below therapeutic.
The thesis
Hypothesized neuroprotection — anti-tau, autophagy, BDNF — at trace doses. This regime: 5mg elemental lithium weekly (~0.7mg/day). Backstory: trace lithium is naturally in drinking water, and reverse osmosis strips it out.
The evidence & the risk
The 2025 Alzheimer's "reversal" was in mice. And the safety margin is narrow: dangerous interactions with NSAIDs, ACE inhibitors, and diuretics; avoid with renal or thyroid disease, or pregnancy.
Bottom lineThe most speculative lever here, and the one with the narrowest toxicity window. Doctor first.
GLP-1, microdosed — the
inflammation lever, not the scale.
The case & the gap
Anti-inflammatory and cardiovascular effects, independent of weight loss. Full-dose data: SELECT 20% fewer cardiac events; STEP 9 cut knee OA pain; CRP down 40–60%. The gap: zero trials at the ~0.125mg/week microdose — plausible mechanism, unproven at this dose.
Our read · n=2
No adverse cardiac signal in us — resting HR and HRV stayed essentially flat, with dips tracking alcohol and poor sleep, not dosing. Anecdotal anti-inflammatory effect: Jason's tennis elbow largely resolved; Mike noted joint aches emerging around a skipped dose.
Bottom lineStrong full-dose evidence, honest microdose uncertainty, suggestive personal signal.
Evidence and safety move
independently.
NMN (cancer double-edge)
Urolithin A
Start with the two that are
proven and safe.
Creatine and Urolithin A: real human evidence, clean safety, no real downside. Add GlyNAC and NMN with eyes open. The last two — lithium and microdosed GLP-1 — only with a doctor and the honesty that the dose is unproven.
The one rule
Treat every compound as a bet with a confidence level, not a fact. Track your own bloodwork — you are the n=1 that matters.
What I'll share
Doses, brands, and the exact panel I watch. The whole point is to copy the proven part and skip the hype.
Happy to sit with anyone who wants to build their version of this.
Six weeks.
Four moves that compound.
I spent a cohort learning to run Claude Code on top of my notes. Most of it was setup. Four moves did the real work — they turn a chatbot into something that does the legwork while I sleep, and gets sharper every time it runs.
All of this I learned in Artem Zhutov's Claude Code cohort — artemzhutov.com. If one thing here lands, take the class.
From a chatbot you re-explain yourself to —
a company OS that runs the firm.
A chatbot forgets you between conversations. The shift: your notes become the firm's memory and Claude the labor on top of it — one operating system for a small company. Seven rungs from "I can talk to it" to "it runs parts of the business."
Not four tips. A flywheel.
| The move | What it gives you | |
|---|---|---|
| 1 | Discipline — keep the context window under 30% | A read you can trust, not one that's fluent and wrong |
| 2 | Structure — the project + templates, not the chat | Work that resumes across days instead of resetting each chat |
| 3 | Leverage — put a skill on a schedule | Briefs, monitors and scorecards that run without me |
| 4 | Compounding — retrospective, the system rewrites itself | Skills that get sharper every time I correct them |
Keep the context window
under 30%.
What it is
Everything the machine can "see" at once is finite. As it fills, quality degrades — and you don't feel it happen. The class taught under 50%. I run tighter. The fix isn't a bigger model; it's a smaller working set: offload research to sub-agents, keep memory lean, clear early.
How I run it
My weekly podcast pipeline fans ~97 ticker searches out to sub-agents and runs each writing stage in a fresh window, so the main thread never clogs. The work gets bigger; the window it thinks in stays small.
What it givesThe read at 25% is one you can trust. At 70% it's confident and quietly wrong.
The project is the unit of work.
Not the chat.
What it is
Left alone, the machine invents fields and improvises structure every time. Templates are the single source of truth. Three nest together: the project holds the goal and a live status; the plan breaks it into phased steps; each session is one work block that logs what happened and hands off. Start, work, hand off, resume — nothing lost when the machine forgets.
How I run it
The /project skill is just those three templates, skillified — one command stamps a project, a plan, or a session, same schema every time. I resume a thread days later from its status block instead of re-explaining it. Company dossiers come off the same idea: one template, every name built the same way.
Open-sourced — clone it: github.com/mikenvt/obsidian-project-skill
What it givesContinuity. The thinking accrues to a project, not a transcript that scrolls away.
Put a skill on a schedule.
Now it works while you sleep.
What it is
The jump from "it does what I ask" to "it works while I'm not watching." A skill you'd run by hand, run on a schedule, becomes a standing capability — the brief written before you wake, the monitor that never sleeps.
The catch
Written rules aren't enforced when it runs alone. The class watched someone's agent install software its own CLAUDE.md forbade. You design checkpoints, not stricter prose. Next slide: what I have running.
What runs without me now.
What one of those crons actually ships.
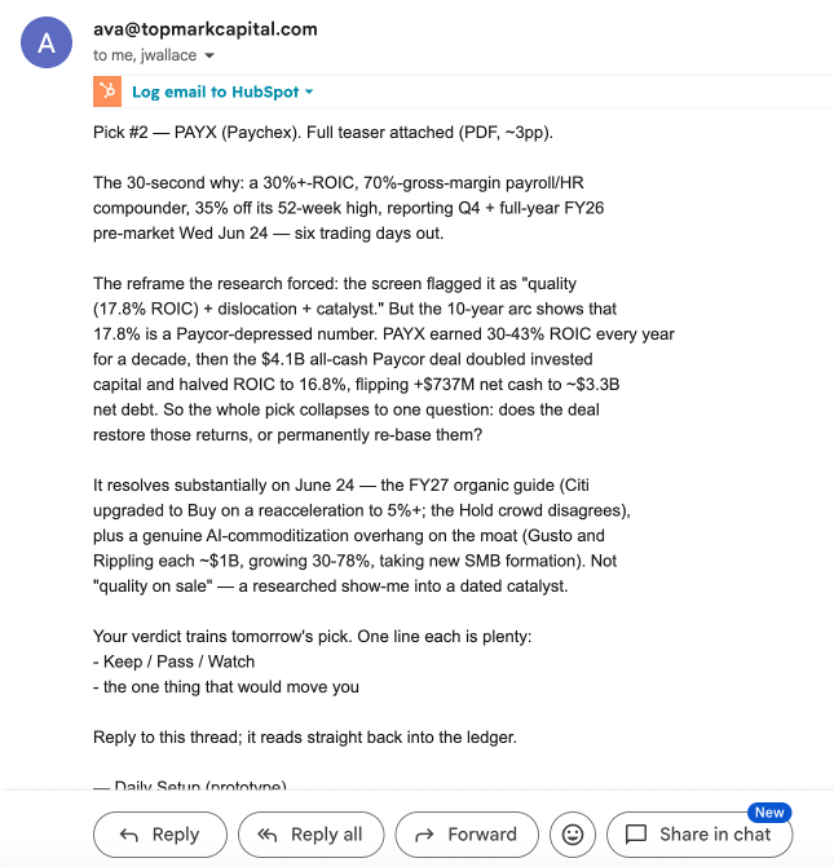

It screens, researches and writes this overnight. My reply — Keep / Pass / Watch, one line — reads straight back into the ledger and trains tomorrow's pick. The verdict is the only input it can't make.
The system rewrites itself.
What it is
After a session, retrospective reads what went wrong — where I corrected it, what it improvised — and folds those lessons back into the skills. The tool I use this week is worse than the one I'll use next month, because it learns from being used.
How I run it
Every correction I make can be written back as a durable rule the system reads next time. Hundreds of them now — each mistake makes the next run better, and I never re-explain the same fix twice.
What it givesA workflow that bends up on its own. It's an asset that improves with use, not a tool that wears out.
Each move makes the next one safe.
You can't automate work you haven't structured, and you can't structure work from a cluttered window. The compounding most people miss isn't the AI getting smarter. It's your system getting smarter around it.
Start with one skill and a context discipline.
The other three follow.
Pick the workflow you repeat most. Write it once as a skill. Keep the window under 30%. Schedule it when you trust it. Run retrospective when it's wrong. That's the whole flywheel — everything else is depth.
Take the class
Artem Zhutov — the Claude Code cohort I went through. The structured path, fastest from zero. artemzhutov.com
Copy a setup
Gary Tan — gbrain + gstack. A public, working setup you can fork and run instead of building from scratch.
Happy to sit with anyone who wants to stand up the first one.
Clean sheet,
what do you build?
I just showed you the machine I run. This is the question building it left open — for a value fund specifically. I have half an answer. I want the room to take it apart.
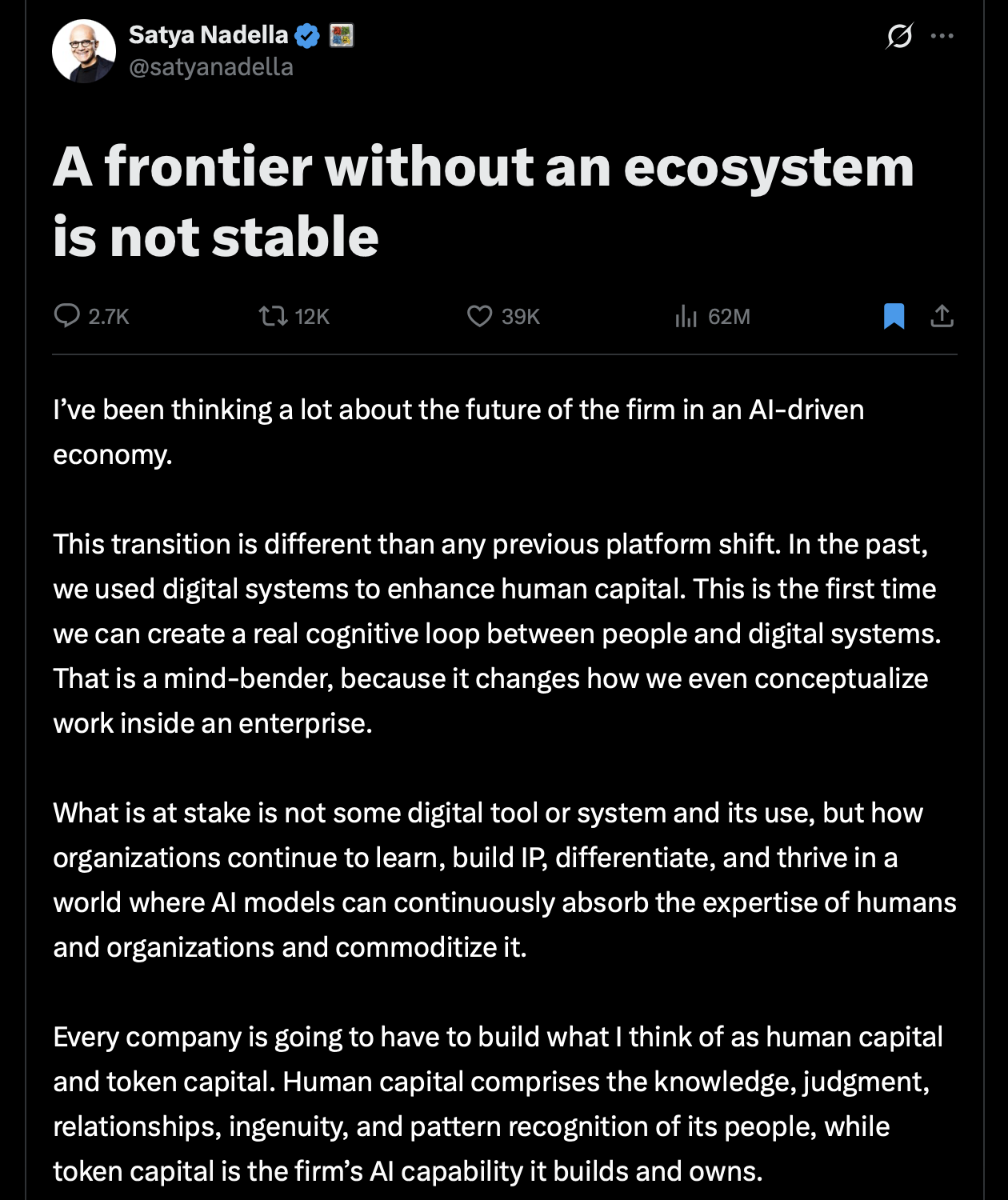
Every layer of the edge
gets commoditized.
Satya's word for it is the same word. The only question left is which layer falls next — and whether you're long or short the firms whose edge depends on it.
What does a value
fund become?
One word for the whole column:
taste is a function, not a vibe.
Deciding which questions are worth asking, and judging whether an answer is true.
AI can answer any question and produce any read. It can't tell you which question matters, or whether its own output is right. That residual is irreducibly human — it's the thing that grades the machine.
| Function | The machine | The human (taste) |
|---|---|---|
| Sourcing / universe | Scans everything, surfaces anomalies | What counts as interesting |
| Diligence / legwork | Eats it whole — filings, models, transcripts | — |
| Underwriting / the read | Produces a first-draft read | Is the read true, or just fluent? |
| Valuation | Runs the mechanics | Which 2–3 assumptions matter |
| Decision / sizing | Recommends; can't bet your capital | Concentration courage |
| Portfolio / risk | Optimizes, flags correlation | Whether you believe in diversification |
| Monitoring | Better than a human — never sleeps | Thesis broken vs. just noisy |
| Capital base | — | Patient money, held through drawdowns |
| Access | — | The room you can't prompt into |